【他のレンジ/シート/ブックを更新する】
1 あるレンジから別レンジを更新
2 あるシートから別シートを更新
3 逆Z式並びで更新
4 セルで指定したシートを更新
5 複数シートを連続更新
6 関数の定義と呼び出し
7 Pythonの汎用型プログラム構成











あるレンジから別レンジを更新
今回は、Python-xlwingsによって、あるレンジからデータを読みとり別レンジへデータを書きこんでみます。
今回から、Python-xlwingsによって漢字学習アプリを作成します。
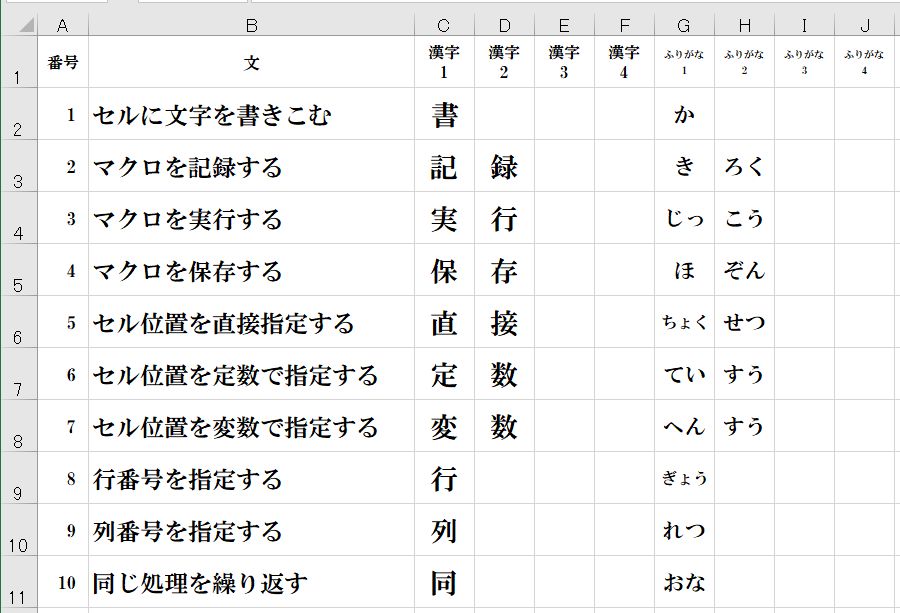
先ず、漢字入力帳のサンプルを次のように作成します。
Pythonプログラムファイルを保存しているフォルダ内に、
上記Excelシート名を『ワークシート1』として、
Excelブック名を『ワークブック810.xlsx』として保存します。
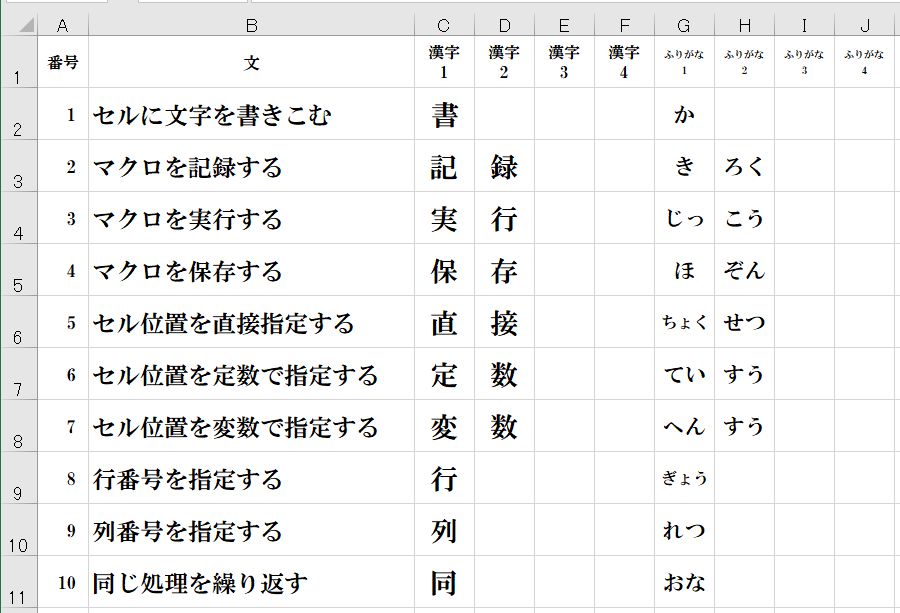
漢字入力帳の仕様は、次の通りです。
(1) B列に問題文を横書きで記述します。
(2) C~F列に問題にしたい漢字を1文字ずつ記述します。
(3) G~J列に問題にしたい漢字のふりがなを1文字ずつ記述します。
(4) A列に番号を記述します。
次に、Pythonプログラムを記述しますが、その仕様は次の通りです。
(1) 漢字入力帳の2~11行を順に読みとる。
(2) 漢字入力帳のB列に記述されている文を1文字ずつ分解しながら漢字学習帳に縦書きで書きこむ。
(3) 漢字入力帳のC~F列に記述されている漢字が漢字学習帳に書きこんだ文字の中にあれば、
そこを空欄のマスにして、併せてそのすぐ右側に、漢字入力帳のG~J列に記述されている
ふりがなを書きこむ。
Pythonプログラムを実行すれば、次のような漢字学習帳が作成されます。
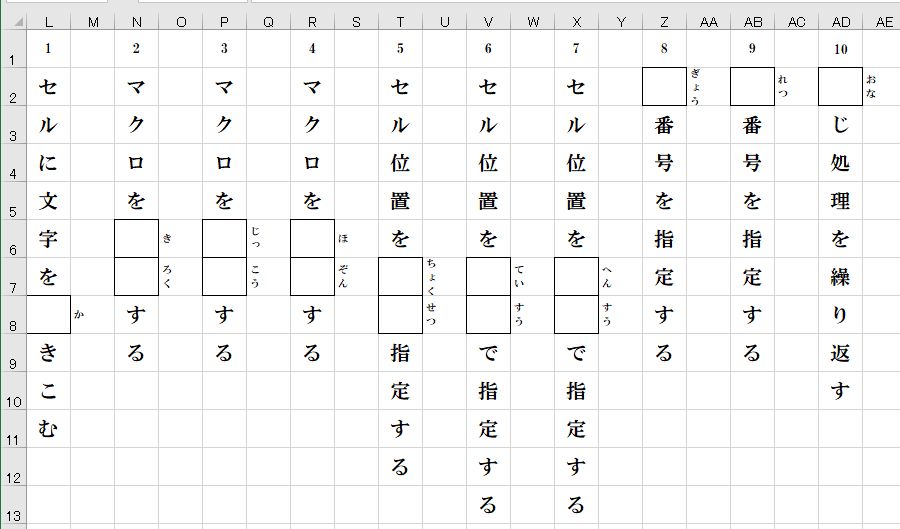
最初に、同一シート内で、漢字入力帳から、漢字学習帳を作成するPythonプログラムをつくってみます。
1. 文字列を1文字ずつ分解しながら縦書きで連続するセルに書きこむ
先ず、Excelの2行目、B列に記述されている文を1文字ずつ分解しながらL列に2行目から
縦書きで1セルずつ書きこんでみます。
xlwingsをxwとしてインポート
Excelファイル『ワークブック810.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
『wb』のExcelシート『ワークシート1』を読みこみsheetオブジェクト『st』を生成
定数『読取列』にB列つまり『2』列を代入
定数『読取行』に『2』行目を代入
定数『列番号』にL列つまり『12』列を代入
定数『最小行』に『2』行目を代入
変数『txt』にセル(『読取行』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を 0 から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『行番号』に『最小行』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
『行のループで複数の文字列を連続分解』でつくったPythonプログラム『PXS7101.py』をそのままコピーして、
新しくPythonプログラム『PXS8011.py』をつくります。
【ソースコードパネル】
# PXS7101.py
import xlwings
wb = xlwings.Book('WkBook3.xlsx')
st = wb.sheets['sheet3']
読取列 = 1
最小列 = 2
行番号 = 3
txt = st.range(行番号, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
ここで、このPythonプログラムをつかって、Pythonコードの構成を説明します。
このPythonコードは、大きくオブジェクト生成部・定数部と処理部に分かれます。
オブジェクト生成部には、定数の宣言を記述します。
定数部には、定数の宣言を記述します。
処理部には、代入文、ループ処理、条件分岐処理、
そして関数・メソッド・プロパティ設定などの処理手順を記述します。
このように、定数部と処理部と分けておくと、Pythonコードが記述しやすくなり、
また、Pythonコードが改修しやすくなります。
先ず、オブジェクト生成部を改修します。
xlwingsをxwとしてインポート。
Excelファイル『ワークブック810.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
『wb』のExcelシート『ワークシート1』を読みこみsheetオブジェクト『st』を生成
import xlwings as xw
wb = xw.Book(’ワークブック810.xlsx’)
st = wb.sheets[’ワークシート1’]
次に、定数部を改修します。
定数『読取列』にB列つまり『2』列を代入
定数『読取行』に『2』行目を代入
定数『列番号』にL列つまり『12』列を代入
定数『最小行』に『2』行目を代入
読取列 = 2
読取行 = 2
列番号 = 12
最小行 = 2
そして、処理部を改修します。
変数『txt』にセル(『読取行』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』:インデックスを 0 から『最大文字数』までカウントアップしながら
以下の処理を繰り返す
変数『行番号』に『最小行』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
【ソースコードパネル】
# PXS8011.py
import xlwings as xw
wb = xw.Book(’ワークブック810.xlsx’)
st = wb.sheets[’ワークシート1’]
読取列 = 2
読取行 = 2
列番号 = 12
最小行 = 2
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
それでは、このPythonプログラムを実行してみます。
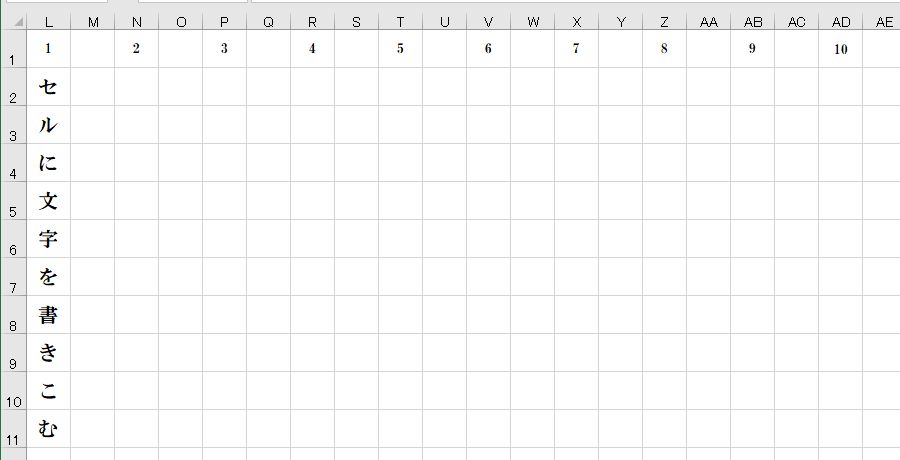
Excelの2行目、B列に記述されている文が1文字ずつ分解されて、L列に2行目から縦書きで
1セルずつ書きこまれました。
2. 文字列の中に特定の文字があれば、該当セルを空欄のマスにする

次は、ExcelのC~F列に記述されている漢字が文字列の中にあれば、該当セルを空欄のマスにしてみます。
xlwingsをxwとしてインポート
Excelファイル『ワークブック810.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
『wb』のExcelシート『ワークシート1』を読みこみsheetオブジェクト『st』を生成
定数『読取列』にB列つまり『2』列を代入
定数『読取行』に『2』行目を代入
定数『漢字最小列』にC列つまり『3』列を代入
定数『漢字最大列』にF列つまり『6』列を代入
定数『列番号』にL列つまり『12』列を代入
定数『最小行』に『2』行目を代入
変数『txt』にセル(『行番号』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を 0 から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『行番号』に『最小行』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
変数『漢字列』を『漢字最小列』から『漢字最大列』+1までカウントアップしながら以下の処理を繰り返す
変数『漢字名』にセル(『読取行』,『漢字列』)の値を代入
変数『漢字名』が空白でないとき
セル(『読取行』,『読取列』)の値から『漢字名』の位置を調べて変数『位置インデックス』に格納
変数『位置インデックス』が0以上のとき
変数『行番号』に『最小行』+『位置インデックス』を代入
変数『列番号』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの周りを実線で囲う
枠領域を空白にする
Pythonプログラム『PXS8011.py』をコピーして、Pythonプログラム『PXS8012.py』をつくります。
オブジェクト生成部については、今回は、変更点はありません。
次に、定数部を改修します。
定数『漢字最小列』にC列つまり『3』列を代入
定数『漢字最大列』にF列つまり『6』列を代入
漢字最小列 = 3
漢字最大列 = 6
そして、処理部に、
『ExcelのC~F列に記述されている漢字が文字列の中にあれば該当セルを空欄のマスにする』
という処理を追加します。
変数『漢字列』を『漢字最小列』から『漢字最大列』+1までカウントアップしながら以下の処理を繰り返す
変数『漢字名』にセル(『読取行』,『漢字列』)の値を代入
変数『漢字名』が空白でないとき
セル(『読取行』,『読取列』)の値から『漢字名』の位置を調べて変数『位置インデックス』に格納
変数『位置インデックス』が0以上のとき
変数『行番号』に『最小行』+『位置インデックス』を代入
変数『列番号』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの周りを実線で囲う
枠領域を空白にする
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = st.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = st.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = st.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).api.Borders.LineStyle = 1
st.range(枠領域).value = ""
【ソースコードパネル】
# PXS8012.py
import xlwings as xw
wb = xw.Book(’ワークブック810.xlsx’)
st = wb.sheets[’ワークシート1’]
読取列 = 2
読取行 = 2
漢字最小列 = 3
漢字最大列 = 6
列番号 = 12
最小行 = 2
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = st.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = st.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = st.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).api.Borders.LineStyle = 1
st.range(枠領域).value = ""
それでは、このPythonプログラムを実行してみます。
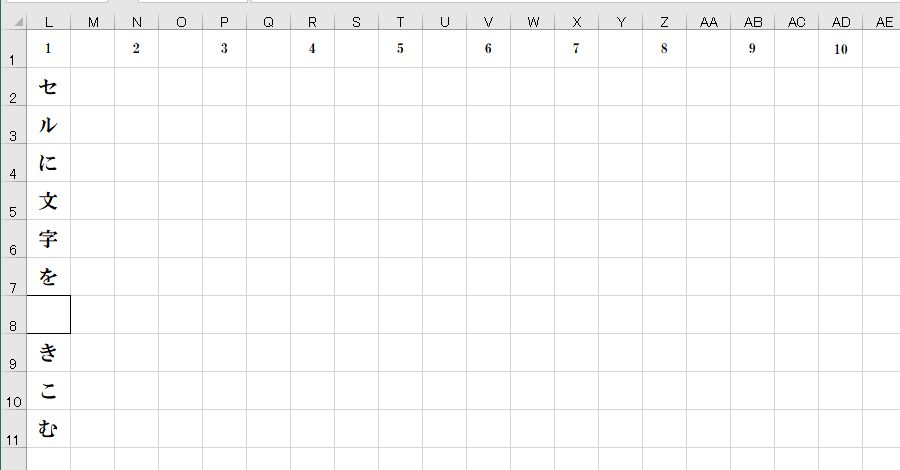
ExcelのセルC2に記述されている漢字『書』があったセルL8が空欄のマスになりました。
3. 文字列の中に特定の文字があれば、該当セルの右側にふりがなを書きこむ

次は、ExcelのC~F列に記述されている漢字が文字列の中にあれば、該当セルのすぐ右側に、
G~J列に記述されているふりがなを書きこみます。
xlwingsをxwとしてインポート
Excelファイル『ワークブック810.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
『wb』のExcelシート『ワークシート1』を読みこみsheetオブジェクト『st』を生成
定数『読取列』にB列つまり『2』列を代入
定数『読取行』に『2』行目を代入
定数『最大枠数』に『4』を代入
定数『漢字最小列』にC列つまり『3』列を代入
定数『漢字最大列』にF列つまり『6』列を代入
定数『列番号』にL列つまり『12』列を代入
定数『最小行』に『2』行目を代入
変数『txt』にセル(『行番号』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を 0 から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『行番号』に『最小行』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
変数『漢字列』を『漢字最小列』から『漢字最大列』+1までカウントアップしながら以下の処理を繰り返す
変数『漢字名』にセル(『読取行』,『漢字列』)の値を代入
変数『漢字名』が空白でないとき
セル(『読取行』,『読取列』)の値から『漢字名』の位置を調べて変数『位置インデックス』に格納
変数『位置インデックス』が0以上のとき
変数『行番号』に『最小行』+『位置インデックス』を代入
変数『列番号』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの周りを実線で囲う
枠領域を空白にする
変数『ふりがな読取列』に『漢字列』+『最大枠数』を代入
変数『ふりがな名』にセル(『読取行』,『ふりがな読取列』)の値を代入
変数『ふりがな名』が空白でないとき
変数『ふりがな列』に『列番号』+ 1 を代入
変数『ふりがな列』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの値に『ふりがな名』を代入
枠領域のセルのフォントサイズを8に設定
枠領域のセルの横方向の配置を左詰めに設定
枠領域のセルの文字の配置を縦方向に設定
枠領域のセルの文字を縮小して全体を表示に設定
Pythonプログラム『PXS8012.py』をコピーして、Pythonプログラム『PXS8013.py』をつくります。
オブジェクト生成部については、今回は、変更点はありません。
次に、定数部を改修します。
定数『最大枠数』に『4』を代入
最大枠数 = 4
そして、処理部に、
『ExcelのC~F列に記述されている漢字が文字列の中にあれば、該当セルのすぐ右側に、
G~J列に記述されているふりがなを書きこむ』という処理を追加します。
変数『ふりがな読取列』に『漢字列』+『最大枠数』を代入
変数『ふりがな名』にセル(『読取行』,『ふりがな読取列』)の値を代入
変数『ふりがな名』が空白でないとき
変数『ふりがな列』に『列番号』+ 1 を代入
変数『ふりがな列』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの値に『ふりがな名』を代入
枠領域のセルのフォントサイズを8に設定
枠領域のセルの横方向の配置を左詰めに設定
枠領域のセルの文字の配置を縦方向に設定
枠領域のセルの文字を縮小して全体を表示に設定
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = st.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = st.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).value = ふりがな名
st.range(枠領域).api.Font.Size = 8
st.range(枠領域).api.HorizontalAlignment = -4131
st.range(枠領域).api.Orientation = -4166
st.range(枠領域).api.ShrinkToFit = True
【ソースコードパネル】
# PXS8013.py
import xlwings as xw
wb = xw.Book(’ワークブック810.xlsx’)
st = wb.sheets[’ワークシート1’]
読取列 = 2
読取行 = 2
最大枠数 = 4
漢字最小列 = 3
漢字最大列 = 6
列番号 = 12
最小行 = 2
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = st.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = st.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = st.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).api.Borders.LineStyle = 1
st.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = st.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = st.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).value = ふりがな名
st.range(枠領域).api.Font.Size = 8
st.range(枠領域).api.HorizontalAlignment = -4131
st.range(枠領域).api.Orientation = -4166
st.range(枠領域).api.ShrinkToFit = True
それでは、このPythonプログラムを実行してみます。
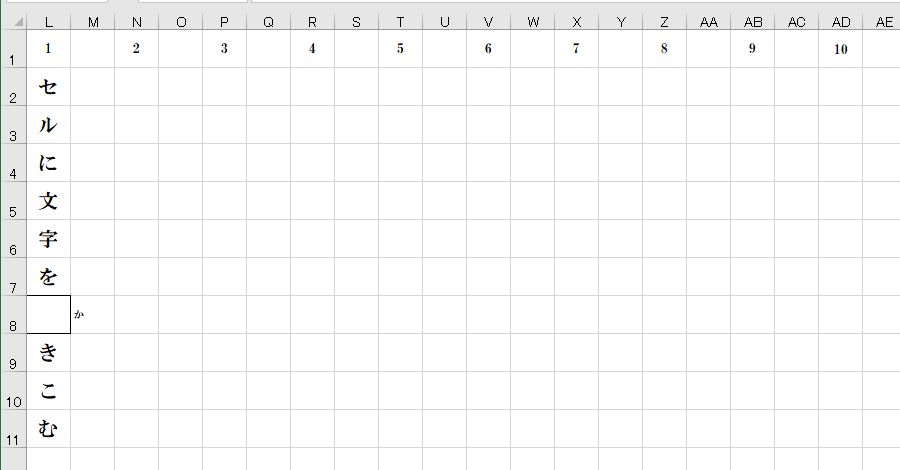
ExcelのセルG2に記述されている漢字『か』がセルM8に書きこまれました。
4. 行のループで漢字学習帳を作成する
Excelの漢字入力帳のB列に記述されている文を1文字ずつ分解しながら、漢字学習帳に2行目から
縦書きで書きこみ、漢字入力帳のC~F列に記述されている漢字が漢字学習帳に書きこんだ文字の中にあれば、
当セルを空欄のマスにして、併せてそのすぐ右側に、漢字入力帳のG~J列に記述されているふりがなを書きこむ。
この一連の処理を、漢字入力帳の最小行から最大行までのループ処理で一気に実行し、L列からAD列まで
瞬時に書きこみます。
xlwingsをxwとしてインポート
Excelファイル『ワークブック810.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
『wb』のExcelシート『ワークシート1』を読みこみsheetオブジェクト『st』を生成
定数『読取列』にB列つまり『2』列を代入
定数『最大枠数』に『4』を代入
定数『漢字最小列』にC列つまり『3』列を代入
定数『漢字最大列』にF列つまり『6』列を代入
定数『読取最小行』に『2』を代入
定数『最小列』にL列つまり『12』列を代入
定数『書込ステップ列』に『2』を代入
定数『最小行』に『2』行目を代入
B列つまり『2』列の最大行を取得し、変数『読取最大行』に格納
変数『列番号』に定数『最小列』の値を代入
変数『読取行』を『読取最小行』から『読取最大行』+1までカウントアップしながら以下の処理を繰り返す
変数『txt』にセル(『行番号』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を 0 から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『行番号』に『最小行』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
変数『漢字列』を『漢字最小列』から『漢字最大列』+1までカウントアップしながら以下の処理を繰り返す
変数『漢字名』にセル(『読取行』,『漢字列』)の値を代入
変数『漢字名』が空白でないとき
セル(『読取行』,『読取列』)の値から『漢字名』の位置を調べて変数『位置インデックス』に格納
変数『位置インデックス』が0以上のとき
変数『行番号』に『最小行』+『位置インデックス』を代入
変数『列番号』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの周りを実線で囲う
枠領域を空白にする
変数『ふりがな読取列』に『漢字列』+『最大枠数』を代入
変数『ふりがな名』にセル(『読取行』,『ふりがな読取列』)の値を代入
変数『ふりがな名』が空白でないとき
変数『ふりがな列』に『列番号』+ 1 を代入
変数『ふりがな列』を列英字名に変換し変数『列英字名』に代入
変数『枠領域』に『列英字名』&『行番号』を代入
枠領域のセルの値に『ふりがな名』を代入
枠領域のセルのフォントサイズを8に設定
枠領域のセルの横方向の配置を左詰めに設定
枠領域のセルの文字の配置を縦方向に設定
枠領域のセルの文字を縮小して全体を表示に設定
変数『列番号』に『列番号』+『書込ステップ列』を代入
Pythonプログラム『PXS8013.py』をコピーして、Pythonプログラム『PXS8014.py』をつくります。
オブジェクト生成部については、今回は、変更点はありません。
次に、定数部を改修します。
定数『読取最小行』に『2』を代入
定数『最小列』にL列つまり『12』列を代入
定数『書込ステップ列』に『2』を代入
読取最小行 = 2
最小列 = 12
書込ステップ列 = 2
そして、処理部を改修します。
Excelの漢字入力帳のB列に記述されている文を1文字ずつ分解しながら、
漢字学習帳に2行目から縦書きで書きこみ、漢字入力帳のC~F列に記述されている漢字が
漢字学習帳に書きこんだ文字の中にあれば、該当セルを空欄のマスにして、
併せてそのすぐ右側に、漢字入力帳のG~J列に記述されているふりがなを書きこむ。
これは、Pythonプログラム『PXS8013.py』の処理部に記述されていることなので、
Pythonプログラム『PXS8013.py』の処理部がブロックとしてそのままつかえます。
Pythonプログラム『PXS8013.py』の処理部を【ブロックA】とします。
【ブロックA】
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = st.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = st.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = st.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).api.Borders.LineStyle = 1
st.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = st.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = st.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).value = ふりがな名
st.range(枠領域).api.Font.Size = 8
st.range(枠領域).api.HorizontalAlignment = -4131
st.range(枠領域).api.Orientation = -4166
st.range(枠領域).api.ShrinkToFit = True
先ず、ExcelのB列の文字が入っているセルの最大行を取得するプログラムコードを追加します。
読取最大行 = st.range(st.cells.last_cell.row, 2).end('up').row
それから、漢字入力帳の最小行:『読取最小行』(2行目)から最大行:『読取最大行』+ 1行にかけて、
各行の処理【ブロックA】をループ処理で実行します。
そこで、【ブロックA】の一つ上の行に、
for 読取行 in range(読取最小行, 読取最大行 + 1):を追加し、
【ブロックA】を1インデントします。
Pythonプログラム『PXS8013.py』までは『列番号』を定数としていましたが、
今回のPythonプログラムから『列番号』を変数に変更します。
そのため、『列番号』のカウントアップが必要となります。
漢字入力帳の最小行から最大行までのループ処理の中で、
『列番号』は行が1行増加するたびに、L列から2列ずつカウントアップしていきます。
そのため、漢字入力帳の最小行から最大行までのループ処理の中に、
列番号 = 列番号 + 書込ステップ列を追加します。
更に、『列番号』の初期値はL列(12列目)なので、そのループ処理の前に、
列番号 = 最小列を追加します。
読取最大行 = st.range(st.cells.last_cell.row, 2).end('up').row
列番号 = 最小列
for 読取行 in range(読取最小行, 読取最大行 + 1):
【ブロックA】
列番号 = 列番号 + 書込ステップ列
【ソースコードパネル】
# PXS8014.py
import xlwings as xw
wb = xw.Book(’ワークブック810.xlsx’)
st = wb.sheets[’ワークシート1’]
読取列 = 2
読取行 = 2
最大枠数 = 4
漢字最小列 = 3
漢字最大列 = 6
読取最小行 = 2
最小列 = 12
書込ステップ列 = 2
最小行 = 2
読取最大行 = st.range(st.cells.last_cell.row, 2).end('up').row
列番号 = 最小列
# ===== 読取行の最小行から最大行へのループにより読取行をカウントアップ =====
for 読取行 in range(読取最小行, 読取最大行 + 1):
txt = st.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = st.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = st.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = st.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).api.Borders.LineStyle = 1
st.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = st.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = st.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
st.range(枠領域).value = ふりがな名
st.range(枠領域).api.Font.Size = 8
st.range(枠領域).api.HorizontalAlignment = -4131
st.range(枠領域).api.Orientation = -4166
st.range(枠領域).api.ShrinkToFit = True
列番号 = 列番号 + 書込ステップ列
それでは、このPythonプログラムを実行してみます。
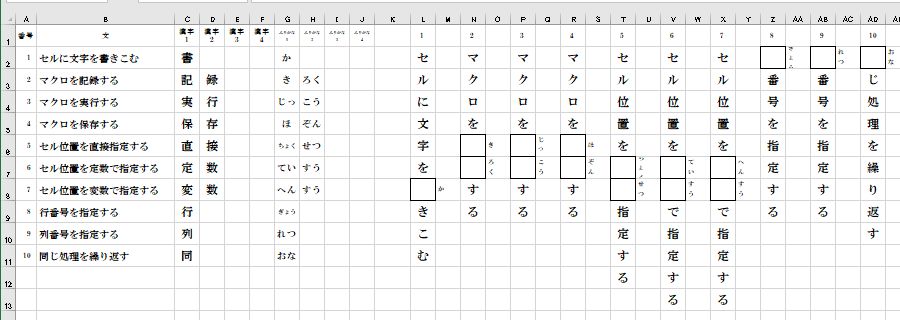
ExcelのL列からAD列にかけて、漢字の書きこみ問題が作成されました。