【他のレンジ/シート/ブックを更新する】
1 あるレンジから別レンジを更新
2 あるシートから別シートを更新
3 逆Z式並びで更新
4 セルで指定したシートを更新
5 複数シートを連続更新
6 関数の定義と呼び出し
7 Pythonの汎用型プログラム構成











セルで指定したシートを更新
今回は、Python-xlwingsによって、あるシートからデータを読みとり
セルで指定した別シートへデータを書きこんでみます。
前回は、『漢字入力帳』シートからデータを読みとり、『漢字学習帳』シートへデータを書きこみました。
今回は、『漢字入力帳』シートからデータを読みとり、『漢字学習帳A』シート、
または、『漢字学習帳B』シートへデータを書きこんでみます。
そこで、その準備として、Excelブック内に、『漢字入力帳』シートと『漢字学習帳A』・『漢字学習帳B』シートを
作成しておきましょう。
Pythonプログラムファイルを保存しているフォルダ内に、
前回使用した『ワークブック830.xlsx』をコピーして『ワークブック841.xlsx』を作成します。
『漢字入力帳』シート
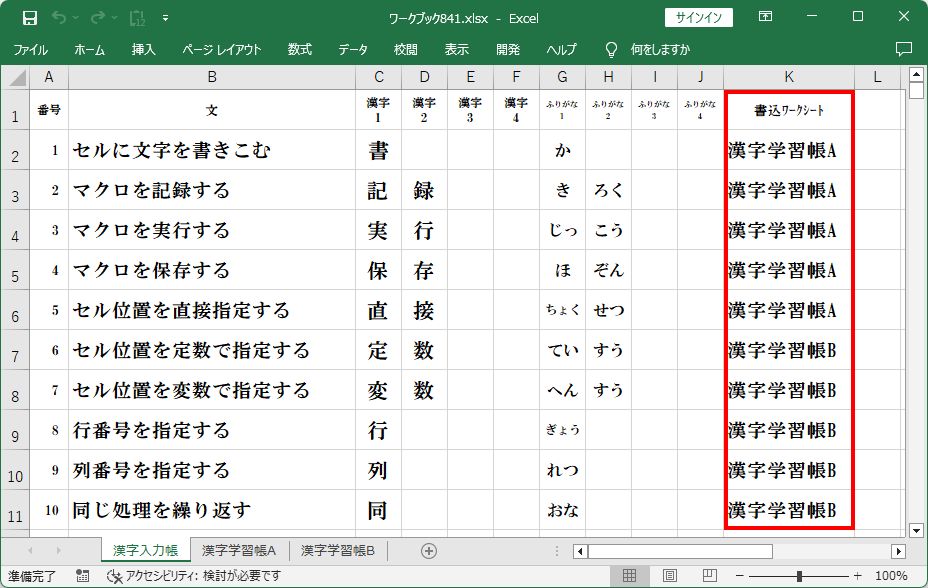
書込ワークシートとして『漢字学習帳A』シートと『漢字学習帳B』シートの
どちらのワークシートに何を書き込むかを予め決めておく必要があります。
書込ワークシートをどのシートにするかを決める方法は何通りもありますが、
今回は、『漢字入力帳』シートのK列に書込ワークシート名を予め記入しておき、
Pythonプログラム実行時に問題番号毎にそれを読みとることにします。
Pythonプログラム『PXS8030.py』をコピーして、Pythonプログラム『PXS8040.py』に名前を変えます。
オブジェクト生成部・定数部を改修します。
Excelファイル『ワークブック841.xlsx』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
定数『書込ワークシート列』に『11』列目を代入
import xlwings as xw
wb = xw.Book(’ワークブック841.xlsx’)
書込ワークシート列 = 11
処理部を改修します。
読取行のカウントアップのループの中で、
『漢字入力帳』シートの書込ワークシート列(11列)の書込ワークシートを変数『WSheet』に格納
『wb』のExcelシート『WSheet』を読みこみsheetオブジェクト『Wst』を生成
WSheet = Est.range(読取行, 書込ワークシート列).value
Wst = wb.sheets[WSheet]
【ソースコードパネル】
# PXS8040.py
import xlwings as xw
wb = xw.Book(’ワークブック841.xlsx’)
Est = wb.sheets[’漢字入力帳’]
読取問題番号列 = 1
読取列 = 2
最大枠数 = 4
漢字最小列 = 3
漢字最大列 = 6
書込ワークシート列 = 11
読取最小行 = 2
# Wst = wb.sheets[’漢字学習帳’]
最大列 = 10
書込列数 = 5
書込ステップ列 = -2
書込問題番号最小行 = 1
書込ステップ行 = 15
読取最大行 = Est.range(Est.cells.last_cell.row, 2).end('up').row
# ===== 読取行の最小行から最大行へのループにより読取行をカウントアップ =====
for 読取行 in range(読取最小行, 読取最大行 + 1):
WSheet = Est.range(読取行, 書込ワークシート列).value
Wst = wb.sheets[WSheet]
問題番号 = Est.range(読取行, 読取問題番号列).value
書込問題番号行 = int((問題番号 - 1) / 書込列数) * 書込ステップ行 \
+ 書込問題番号最小行
最小行 = 書込問題番号行 + 1
列番号 = 最大列 + ((問題番号 - 1) % 書込列数) * 書込ステップ列
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(書込問題番号行)
Wst.range(枠領域).value = 問題番号
Wst.range(枠領域).api.Font.Size = 10
txt = Est.range(読取行, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
Wst.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = Est.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = Est.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).api.Borders.LineStyle = 1
Wst.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = Est.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = Wst.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).value = ふりがな名
Wst.range(枠領域).api.Font.Size = 8
Wst.range(枠領域).api.HorizontalAlignment = -4131
Wst.range(枠領域).api.Orientation = -4166
Wst.range(枠領域).api.ShrinkToFit = True
それでは、このPythonプログラムを実行してみます。
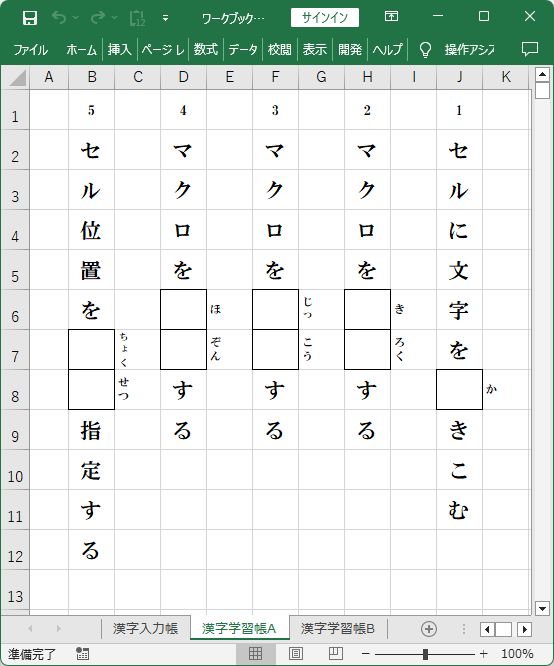
_ 『漢字学習帳A』シート
_ 『漢字学習帳B』シート
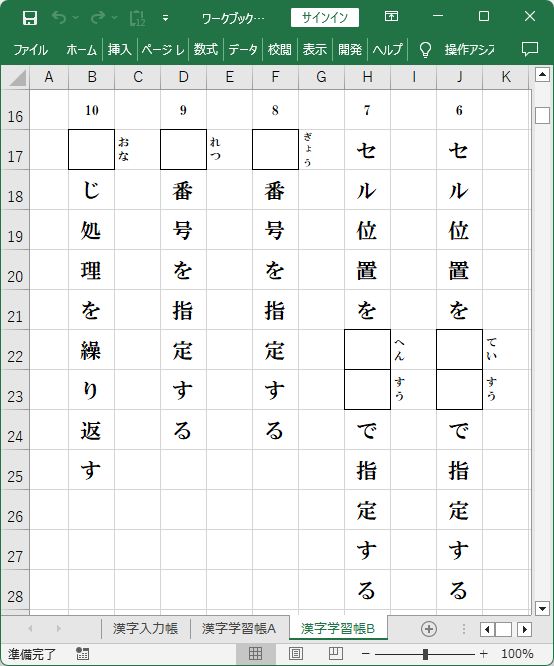
『漢字入力帳』シートに用意した10問の漢字文字列が、文字分割されて
『漢字学習帳A』シートに1~5問、『漢字学習帳B』シートに6~10問が書きこまれました。