【他のレンジ/シート/ブックを更新する】
4 セルで指定したシートを更新
5 複数シートを連続更新
6 関数の定義と呼び出し
7 Pythonの汎用型プログラム構成
8 定数で指定したブックを更新
9 セルで指定したブックを更新
10 Excel_VBA/マクロからPythonを実行しブックを更新











Pythonの汎用型プログラム構成
今回は、Python-xlwingsによって、Pythonの汎用型プログラム構成に則って
あるシートからデータを読みとり二つの別シートへデータを連続して書きこんでみます。
Pythonプログラム『PXS8070.py』を汎用型プログラム構成で作成します。
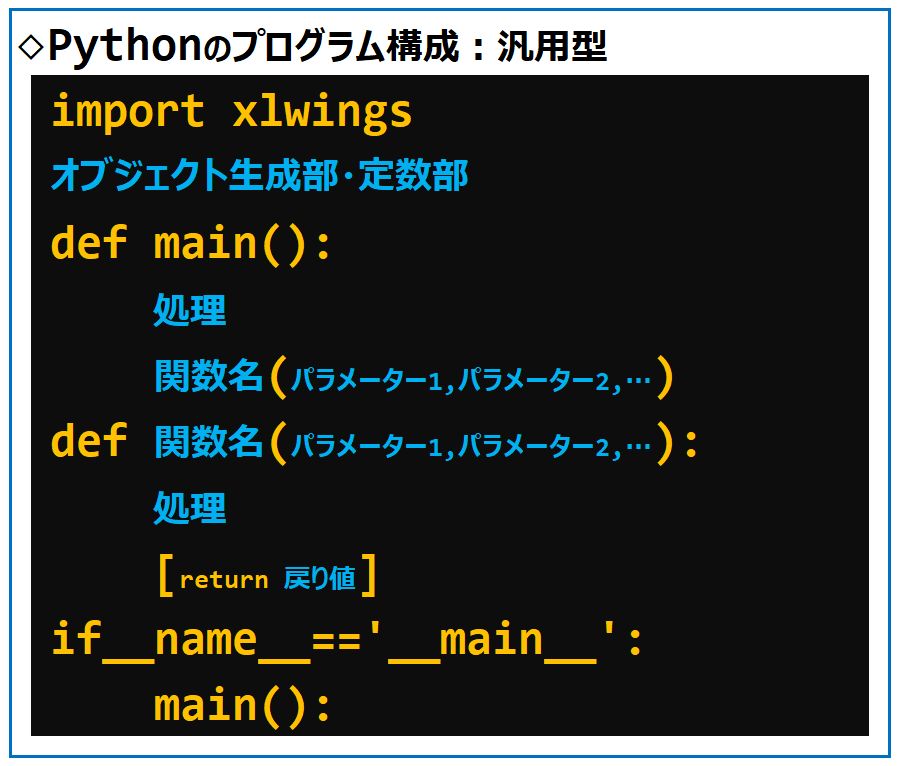
Pythonのプログラム構成:汎用型の書式は次の通りです。
Pythonプログラムの作り方によっては、モジュールを『import』によって別のモジュールから呼び出す
ことがあります。
モジュールを作るときは、単体で実行するだけでなく、他のモジュールにもインポートして使えるように
しておくこともできるのです。
そこで、モジュールがインポートされたときに、実行されても良い関数と実行されたらまずい処理を
明確に区別するために、Pythonの汎用型プログラム構成は、上記の図のようになります。

main関数を定義し、当モジュールが直接起動されたときのみ実行するメイン処理を記述します。

先頭と末尾が2個のアンダースコア(__)になっている名前は、Pythonが使う変数として予約されています。
当モジュールを直接実行した場合には、『__name__』に『'__main__'』という値が入ってきます。
そこで、『if __name__ == '__main__':』とは、(別のモジュールから呼び出されたのではなく)
『当モジュールが直接起動されたとき』という意味です。
次に、この『当モジュールが直接起動されたとき』のみ、実行するメイン処理を記述します。
ここには、main関数を呼び出すという記述のしかたが便利です。
というのは、一つのモジュールに複数の関数を記述するときは、先頭行附近にメイン処理があった方が
モジュール全体を俯瞰しやすくなり、メイン処理を記述しながら個々の関数を一つ一つ追記しやすくなるからです。
『漢字問題集』、または、『漢字解答集』を作成する共通の処理を関数『kosin_kanjigakusyutyo』として定義、
その関数『kosin_kanjigakusyutyo』を『漢字問題集』の作成、及び、『漢字解答集』の作成でそれぞれ呼び出す
メイン処理を関数『main』として定義、
『if __name__ == '__main__':』のときに関数『main』を呼び出す
といった仕様のPythonプログラム『PXS8070.py』を作成します。
Pythonプログラム『PXS8060.py』をコピーして、Pythonプログラム『PXS8070.py』に名前を変えます。
関数『main』を定義します。
関数『main』を定義
引数『WSheet』に定数『WSheetMD』を格納して関数『kosin_kanjigakusyutyo』を呼び出し
引数『WSheet』に定数『WSheetKT』を格納して関数『kosin_kanjigakusyutyo』を呼び出し
def main():
kosin_kanjigakusyutyo(WSheetMD)
kosin_kanjigakusyutyo(WSheetKT)
『if __name__ == '__main__':』のときに関数『main』を呼び出します。
if __name__ == '__main__':
main()
ソースコードは次のようになります。
【ソースコードパネル】
# PXS8070.py
import xlwings as xw
wb = xw.Book(’ワークブック842.xlsx’)
Est = wb.sheets[’漢字入力帳’]
読取問題番号列 = 1
読取列 = 2
最大枠数 = 4
漢字最小列 = 3
漢字最大列 = 6
読取最小行 = 2
読取最大行 = Est.range(Est.cells.last_cell.row, 2).end('up').row
WSheetMD = '漢字問題集'
WSheetKT = '漢字解答集'
最大列 = 10
書込列数 = 5
書込ステップ列 = -2
書込問題番号最小行 = 1
書込ステップ行 = 15
def main():
kosin_kanjigakusyutyo(WSheetMD)
kosin_kanjigakusyutyo(WSheetKT)
def kosin_kanjigakusyutyo(WSheet):
Wst = wb.sheets[WSheet]
# ===== 読取行の最小行から最大行へのループにより読取行をカウントアップ =====
for 読取行 in range(読取最小行, 読取最大行 + 1):
問題番号 = Est.range(読取行, 読取問題番号列).value
書込問題番号行 = int((問題番号 - 1) / 書込列数) * 書込ステップ行 \
+ 書込問題番号最小行
最小行 = 書込問題番号行 + 1
列番号 = 最大列 + ((問題番号 - 1) % 書込列数) * 書込ステップ列
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(書込問題番号行)
Wst.range(枠領域).value = 問題番号
Wst.range(枠領域).api.Font.Size = 10
txt = Est.range(読取行, 読取列).value
最大文字数 = len(txt)
# == 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ ==
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
Wst.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = Est.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = Est.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).api.Borders.LineStyle = 1
if WSheet == WSheetMD:
Wst.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = Est.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = Wst.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).value = ふりがな名
Wst.range(枠領域).api.Font.Size = 8
Wst.range(枠領域).api.HorizontalAlignment = -4131
Wst.range(枠領域).api.Orientation = -4166
Wst.range(枠領域).api.ShrinkToFit = True
if __name__ == '__main__':
main()
それでは、このPythonプログラムを実行してみます。
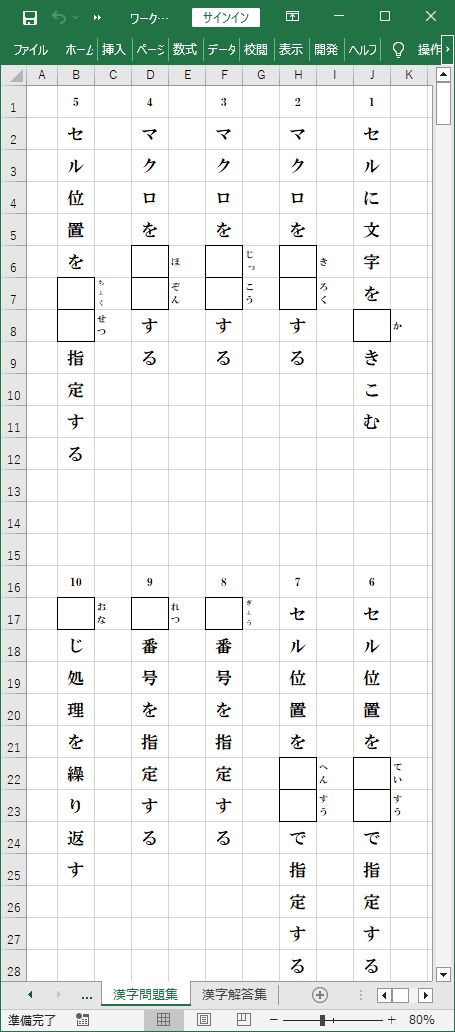
_ 『漢字問題集』シート
_ 『漢字解答集』シート
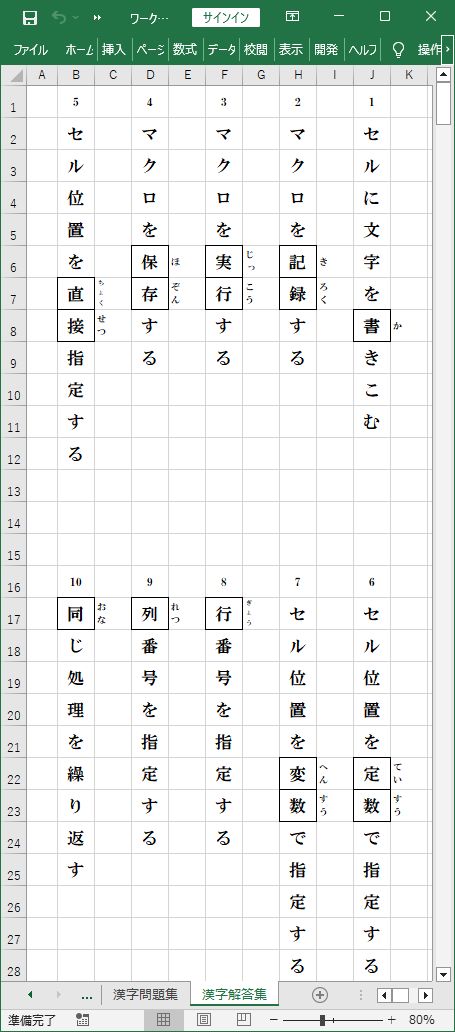
『漢字入力帳』シートに用意した10問の漢字文字列が、出題漢字を空欄にした『漢字問題集』シートと、
出題漢字をそのまま残した『漢字解答集』シートへ、書きこまれました。