【他のレンジ/シート/ブックを更新する】
5 複数シートを連続更新
6 関数の定義と呼び出し
7 Pythonの汎用型プログラム構成
8 定数で指定したブックを更新
9 セルで指定したブックを更新
10 Excel_VBA/マクロからPythonを実行しブックを更新
11 フルパスを指定したブックを更新











定数で指定したブックを更新
今回は、Python-xlwingsによって定数で指定したブックからデータを読みとり
定数で指定した別ブックへデータを書きこんでみます。
あるブックのセルから別ブックのセルに値を代入するときは、
先ず、入力ブックのブックオブジェクトを生成、そのブック内にある入力シートオブジェクトを生成、
次に、出力ブックのブックオブジェクトを生成、そのブック内にある出力シートオブジェクトを生成、
そして、入力シートのセルの値を出力シートのセルの値に代入します。

前回は、同一ブック内で、入力シートからデータを読みとり、出力シートへデータを書きこみました。
今回は、入力ブックからデータを読みとり、出力ブックへデータを書きこみます。
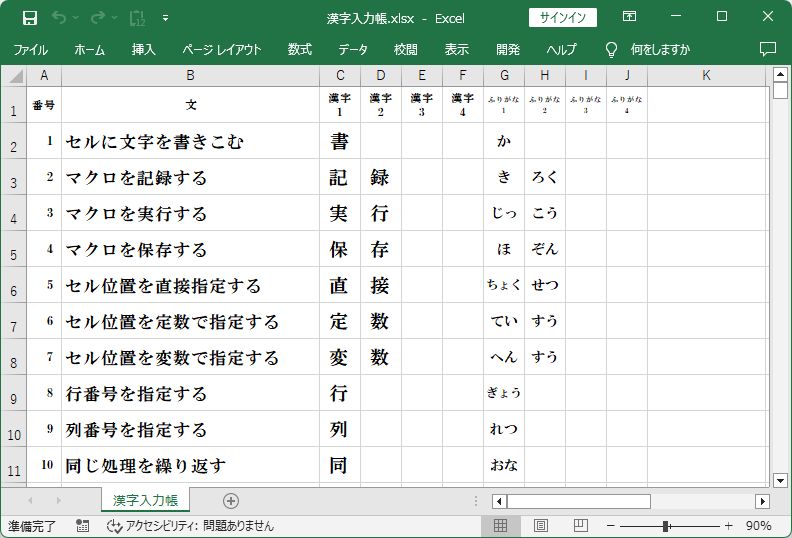
具体的には、『漢字入力帳.xlsx』からデータを読みとり、
『漢字問題集.xlsx』、及び、『漢字解答集.xlsx』へ連続してデータを書きこみます。
Pythonプログラムファイルを保存しているフォルダ内に、
10問の漢字文字列を用意した『漢字入力帳.xlsx』、白紙の『漢字問題集.xlsx』・『漢字解答集.xlsx』
を作成しておきます。
『漢字問題集』、または、『漢字解答集』を作成する共通の処理を関数『kosin_kanjigakusyutyo』として定義、
その関数『kosin_kanjigakusyutyo』を『漢字問題集』の作成、及び、『漢字解答集』の作成でそれぞれ呼び出す
メイン処理を関数『main』として定義、
『if __name__ == '__main__':』のときに関数『main』を呼び出す
といった仕様のPythonプログラム『PXS8080.py』を作成します。
Pythonプログラム『PXS8070.py』をコピーして、Pythonプログラム『PXS8080.py』に名前を変えます。
オブジェクト生成部・定数部を改修します。
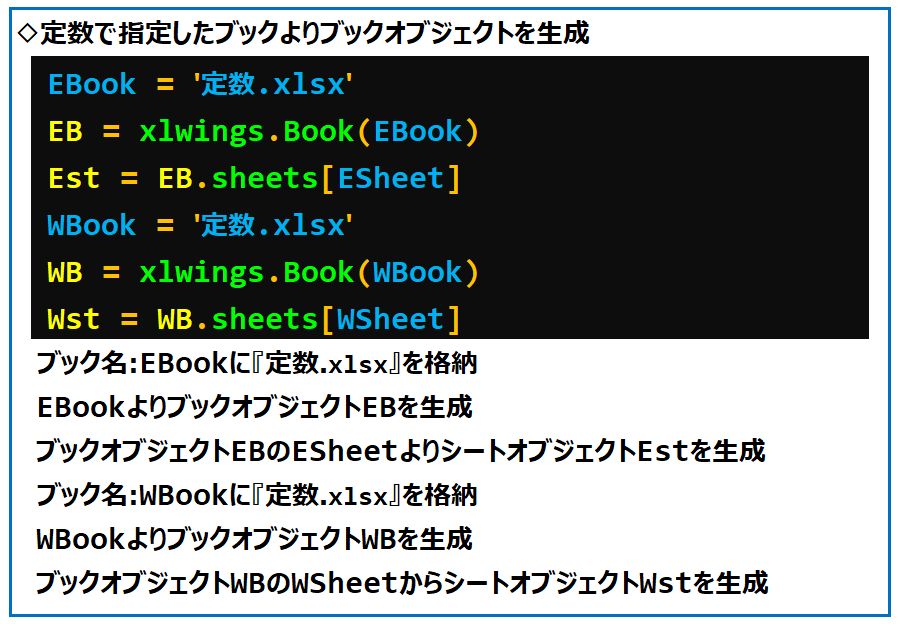
定数『EBook』に『漢字入力帳.xlsx』を格納
定数『EBook』よりブックオブジェクト『EB』を生成
ブックオブジェクト『EB』のシート『漢字入力帳』よりシートオブジェクト『Est』を生成
定数『WBookMD』に『漢字問題集.xlsx』を格納
定数『WBookKT』に『漢字解答集.xlsx』を格納
定数『WSheetMD』に『漢字問題集』を格納
定数『WSheetKT』に『漢字解答集』を格納
import xlwings as xw
EBook = '漢字入力帳.xlsx'
EB = xw.Book(EBook)
Est = EB.sheets['漢字入力帳']
WBookMD = '漢字問題集.xlsx'
WBookKT = '漢字解答集.xlsx'
WSheetMD = '漢字問題集'
WSheetKT = '漢字解答集'
『漢字問題集』、または、『漢字解答集』を作成する関数『kosin_kanjigakusyutyo』を改修します。
引数に『WBook』、『WSheet』を備えた関数『kosin_kanjigakusyutyo』を定義
ブック引数『WBook』よりブックオブジェクト『WB』を生成
ブックオブジェクト『WB』のシート引数『WSheet』よりシートオブジェクト『Wst』を生成
def kosin_kanjigakusyutyo(WBook, WSheet):
WB = xw.Book(WBook)
Wst = WB.sheets[WSheet]
関数『main』を改修します。
関数『main』を定義
引数『WBook』に定数『WBookMD』、引数『WSheet』に定数『WSheetMD』を格納して
関数『kosin_kanjigakusyutyo』を呼び出し
引数『WBook』に定数『WBookKT』、引数『WSheet』に定数『WSheetKT』を格納して
関数『kosin_kanjigakusyutyo』を呼び出し
def main():
kosin_kanjigakusyutyo(WBookMD, WSheetMD)
kosin_kanjigakusyutyo(WBookKT, WSheetKT)
ソースコードは次のようになります。
【ソースコードパネル】
# PXS8080.py
import xlwings as xw
EBook = '漢字入力帳.xlsx'
EB = xw.Book(EBook)
Est = EB.sheets['漢字入力帳']
読取問題番号列 = 1
読取列 = 2
最大枠数 = 4
漢字最小列 = 3
漢字最大列 = 6
読取最小行 = 2
読取最大行 = Est.range(Est.cells.last_cell.row, 2).end('up').row
WBookMD = '漢字問題集.xlsx'
WBookKT = '漢字解答集.xlsx'
WSheetMD = '漢字問題集'
WSheetKT = '漢字解答集'
最大列 = 10
書込列数 = 5
書込ステップ列 = -2
書込問題番号最小行 = 1
書込ステップ行 = 15
def main():
kosin_kanjigakusyutyo(WBookMD, WSheetMD)
kosin_kanjigakusyutyo(WBookKT, WSheetKT)
def kosin_kanjigakusyutyo(WBook, WSheet):
WB = xw.Book(WBook)
Wst = WB.sheets[WSheet]
# ===== 読取行の最小行から最大行へのループにより読取行をカウントアップ =====
for 読取行 in range(読取最小行, 読取最大行 + 1):
問題番号 = Est.range(読取行, 読取問題番号列).value
書込問題番号行 = int((問題番号 - 1) / 書込列数) * 書込ステップ行 \
+ 書込問題番号最小行
最小行 = 書込問題番号行 + 1
列番号 = 最大列 + ((問題番号 - 1) % 書込列数) * 書込ステップ列
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(書込問題番号行)
Wst.range(枠領域).value = 問題番号
Wst.range(枠領域).api.Font.Size = 10
txt = Est.range(読取行, 読取列).value
最大文字数 = len(txt)
# == 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ ==
for 位置インデックス in range(0, 最大文字数):
行番号 = 最小行 + 位置インデックス
Wst.range(行番号, 列番号).value = txt[位置インデックス]
# ===== 漢字列の最小列から最大列へのループにより漢字列をカウントアップ =====
for 漢字列 in range(漢字最小列, 漢字最大列 + 1):
漢字名 = Est.range(読取行, 漢字列).value
if 漢字名 is not None:
位置インデックス = Est.range(読取行, 読取列).value.find(漢字名)
if 位置インデックス >= 0:
行番号 = 最小行 + 位置インデックス
列英字名 = Wst.range(1, 列番号).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).api.Borders.LineStyle = 1
if WSheet == WSheetMD:
Wst.range(枠領域).value = ""
ふりがな読取列 = 漢字列 + 最大枠数
ふりがな名 = Est.range(読取行, ふりがな読取列).value
if ふりがな名 is not None:
ふりがな列 = 列番号 + 1
列英字名 = Wst.range(1, ふりがな列).get_address \
(False, False).replace("1", "")
枠領域 = 列英字名 + str(行番号)
Wst.range(枠領域).value = ふりがな名
Wst.range(枠領域).api.Font.Size = 8
Wst.range(枠領域).api.HorizontalAlignment = -4131
Wst.range(枠領域).api.Orientation = -4166
Wst.range(枠領域).api.ShrinkToFit = True
if __name__ == '__main__':
main()
それでは、このPythonプログラムを実行してみます。
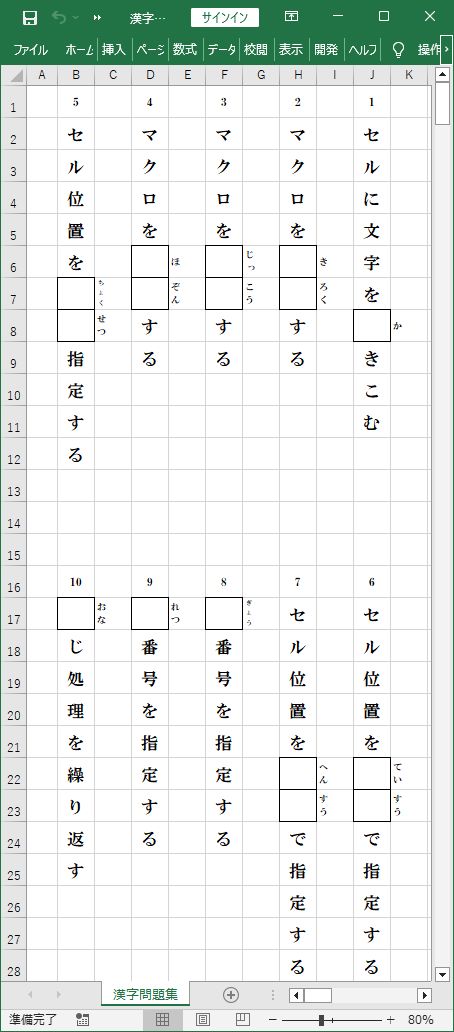
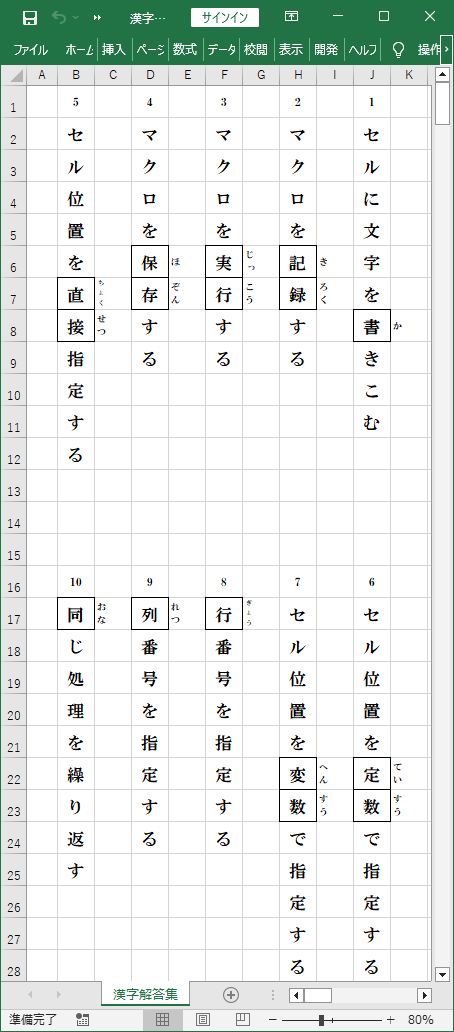
『漢字入力帳.xlsx』からデータが読みとられ、『漢字問題集.xlsx』・『漢字解答集.xlsx』へ
データが書きこまれました。