【関数・メソッド・プロパティ設定をつかう】
7 文字列のループで1文字ずつ分解
8 文字が入っているセルの最大行を取得
9 文字が入っているセルの最大列を取得
10 行のループで複数の文字列を連続分解
11 列のループで複数の文字列を連続分解
12 指定した行番号と列番号のセル番地を取得
13 特定の文字列を指定文字列に置き換え











行のループで複数の文字列を連続分解
今回は、Python-xlwingsで、
ブラケット1文字スライス書式と文字列のループ処理、更に、行のループ処理を組み合わせて、
複数行の文字列を左端から右端まで順に1文字ずつ分解してみます。
予め、次のようなExcelシート『sheet3』を用意して、
Excelブック名を『WkBook3.xlsx』として保存します。
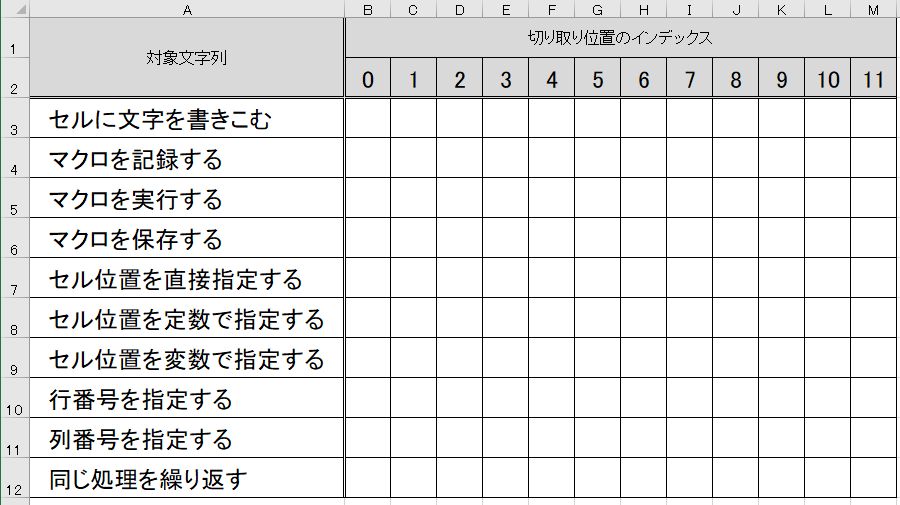
3行目を指定して、
A列のセルから取得した文字列を左端から右端まで順に1文字ずつ分解した文字を、
B列からM列までのセルに順に格納してみます。
xlwingsをインポート
Excelファイル『Wkbook3』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
Excelシート『sheet3』を読みこみsheetオブジェクト『st』を生成
定数『読取列』にA列つまり『1』列を代入
定数『最小列』にB列つまり『2』列を代入
定数『行番号』に『3』行目を代入
変数『txt』にセル(『行番号』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を0から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『列番号』に『最小列』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
【ソースコードパネル】
# PXS7101.py
import xlwings
wb = xlwings.Book('WkBook3.xlsx')
st = wb.sheets['sheet3']
読取列 = 1
最小列 = 2
行番号 = 3
txt = st.range(行番号, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
それでは、そのPythonプログラムを実行してみます。
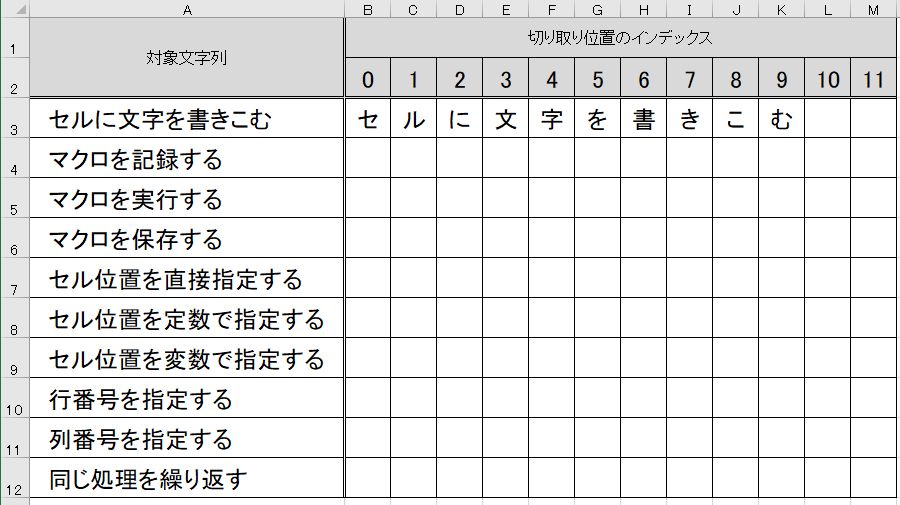
2列目(B列)から11列目(K列)までのセルに『セ』『ル』『に』『文』『字』『を』『書』『き』『こ』『む』が、
書きこまれました。
2. 行のループでセルの文字列を1文字ずつ連続分解
3行目から12行目にかけて、
A列のセルから取得した文字列を左端から右端まで順に1文字ずつ分解した文字を、
B列からM列までのセルに順に格納してみます。
xlwingsをインポート
Excelファイル『Wkbook3』をメモリ上に読みこみWorkbookオブジェクト『wb』を生成
Excelシート『sheet3』を読みこみsheetオブジェクト『st』を生成
変数『読取列』にA列つまり『1』列を代入
変数『最小列』にB列つまり『2』列を代入
変数『開始行』に『3』行目を代入
1列目の最大行を取得し、変数『最大行』に格納
変数『終了行』に『最大行』+1を代入
変数『行番号』を『開始行』から『終了行』までカウントアップしながら以下の処理を繰り返す
変数『txt』にセル(『行番号』,『読取列』)の値を代入
変数『txt』から文字数を取得し、変数『最大文字数』に格納
変数『位置インデックス』を0から『最大文字数』までカウントアップしながら以下の処理を繰り返す
変数『列番号』に『最小列』+『位置インデックス』を代入
セル(『行番号』,『列番号』)の値に変数『txt』から取得した『位置インデックス』の文字を代入
【ソースコードパネル】
# PXS7102.py
import xlwings
wb = xlwings.Book('WkBook3.xlsx')
st = wb.sheets['sheet3']
読取列 = 1
最小列 = 2
開始行 = 3
最大行 = st.range(st.cells.last_cell.row, 1).end('up').row
終了行 = 最大行 + 1
# ===== 行番号の開始行から終了行へのループにより行番号をカウントアップ =====
for 行番号 in range(開始行, 終了行):
txt = st.range(行番号, 読取列).value
最大文字数 = len(txt)
# ===== 文字列の先頭文字から最終文字へのループにより位置インデックスをカウントアップ =====
for 位置インデックス in range(0, 最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = txt[位置インデックス]
それでは、そのPythonプログラムを実行してみます。
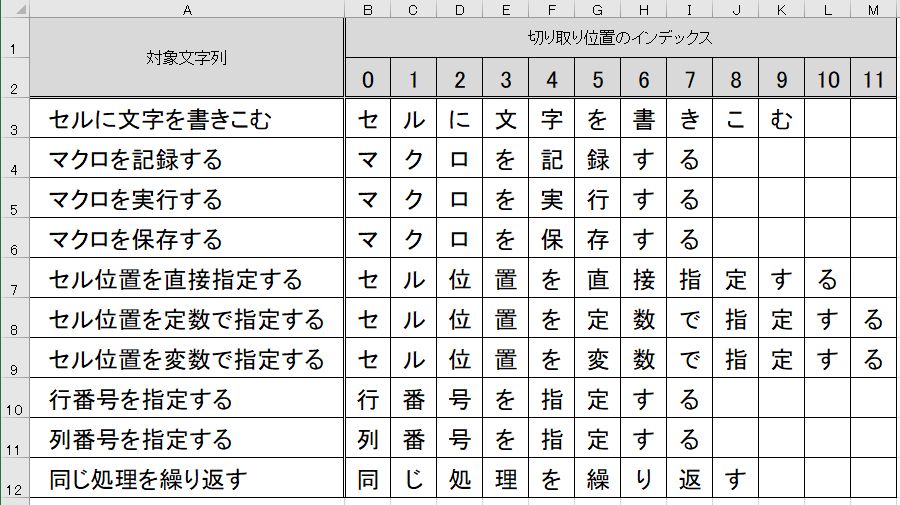
3行目から12行目にかけて、A列のセルから取得した文字列を左端から右端まで
順に1文字ずつ分解した文字が、2列目(B列)から13列目(M列)までのセルに順に書きこまれました。
このように、ブラケット1文字スライス書式と文字列のループ処理、
更に、行のループ処理を組み合わせると、
複数行の文字列を左端から右端まで順に1文字ずつ分解することができます。