【関数・メソッド・プロパティ設定をつかう】
4 三つのブラケットスライス書式をつかう
5 文字列の指定位置から1文字を取得
6 文字列の文字数を取得
7 文字列のループで1文字ずつ分解
8 文字が入っているセルの最大行を取得
9 文字が入っているセルの最大列を取得
10 行のループで複数の文字列を連続分解











文字列のループで1文字ずつ分解
今回は、Pythonで対象文字列を1文字ずつ分解する処理をループ処理で一つにまとめてみます。
1. 文字列のループで1文字ずつ分解
予め、次のようなExcelシート『sheet2』を用意して、Excelブック名を『WkBook2.xlsx』として保存します。
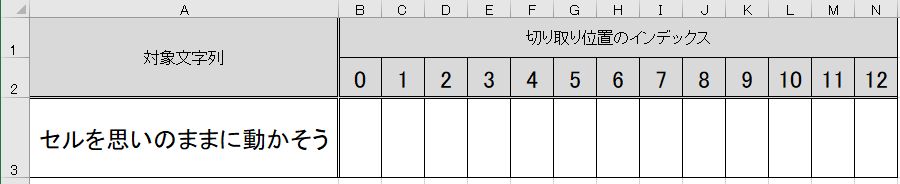
この『WkBook2.xlsx』の『sheet2』を読みこみます。
xlwingsをつかいPythonで既存Excelを読みこみ操作するときは、
Workbookファイルをメモリ上に読みこむと同時にWorkbookオブジェクトを生成、
( 『xlwingsをつかい既存Workbookを読みこみファイル保存』参照 )
更に、sheetオブジェクトを生成して、そのsheetを操作します。
Workbookオブジェクト名を『wb』、sheetオブジェクト名を『st』とします。
ソースコードパネルに
import xlwings
wb = xlwings.Book('WkBook2.xlsx')
st = wb.sheets['sheet2']
と記述しておきます。
定数『行番号』を『3』に、定数『最小列』を『2』に、定数『最大文字数』を『13』に固定します。
行番号 = 3
最小列 = 2
最大文字数 = 13
と記述します。
次に、列番号を変数『列番号』、切り取り位置のインデックスを変数『位置インデックス』とします。
1文字目から『最大文字数』まで1文字ずつ『位置インデックス』をカウントアップしていきながら、
そのつどセルA3の値を1文字ずつ読みとり、セル(行番号, 列番号)に書きこみます。
ここで、『最小列』・『位置インデックス』と『列番号』の等式を整理してみます。
『最小列』が『2』、かつ、
『位置インデックス』が 『0』のとき、『列番号』はB列つまり 『2』列
『位置インデックス』が 『1』のとき、『列番号』はC列つまり 『3』列
『位置インデックス』が 『2』のとき、『列番号』はD列つまり 『4』列
『位置インデックス』が 『3』のとき、『列番号』はE列つまり 『5』列
『位置インデックス』が 『4』のとき、『列番号』はF列つまり 『6』列
『位置インデックス』が 『5』のとき、『列番号』はG列つまり 『7』列
『位置インデックス』が 『6』のとき、『列番号』はH列つまり 『8』列
『位置インデックス』が 『7』のとき、『列番号』はI列つまり 『9』列
『位置インデックス』が 『8』のとき、『列番号』はJ列つまり『10』列
『位置インデックス』が 『9』のとき、『列番号』はK列つまり『11』列
『位置インデックス』が『10』のとき、『列番号』はL列つまり『12』列
『位置インデックス』が『11』のとき、『列番号』はM列つまり『13』列
『位置インデックス』が『12』のとき、『列番号』はN列つまり『14』列
ということは、
列番号 = 最小列 + 位置インデックス
という等式が成り立ちます。
for 位置インデックス in range(0,最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = st.range('A3').value[位置インデックス]
と記述します。
【ソースコードパネル】
import xlwings
wb = xlwings.Book('WkBook2.xlsx')
st = wb.sheets['sheet2']
行番号 = 3
最小列 = 2
最大文字数 = 13
for 位置インデックス in range(0,最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = st.range('A3').value[位置インデックス]
それでは、そのPythonプログラムを実行してみましょう。

セルB3~N3に『セ』『ル』『を』『思』『い』『の』『ま』『ま』『に』『動』『か』『そ』『う』
が、書きこまれました。
2. 文字列の文字数を取得後、文字列のループで1文字ずつ分解
先ほど、対象文字列を1文字ずつ分解する処理をループ処理で一つにまとめてみましたが、
ループの終了値つまり『最大文字数』を『13』に固定していました。
ループの終了値を毎回人が数えていては手間がかかるし時間もかかるので、
Pythonに計算してもらうようにします。
いったん全てのセルB3~N3の値をクリアします。
ループの終了値つまり最大文字数:MaxStrを取得するために、len関数をつかってみます。
引数としてセルA3から取得した文字列を渡してから、
文字数を受け取り、変数『最大文字数』に格納してみます。
最大文字数 = len(st.range('A3').value)
ループ処理の前処理として、これをループ処理より先に記述します。
【ソースコードパネル】
import xlwings
wb = xlwings.Book('WkBook2.xlsx')
st = wb.sheets['sheet2']
行番号 = 3
最小列 = 2
最大文字数 = len(st.range('A3').value)
for 位置インデックス in range(0,最大文字数):
列番号 = 最小列 + 位置インデックス
st.range(行番号, 列番号).value = st.range('A3').value[位置インデックス]
それでは、そのPythonプログラムを実行してみましょう。
セルB3~N3に『セ』『ル』『を』『思』『い』『の』『ま』『ま』『に』『動』『か』『そ』『う』
が、書きこまれました。
試しに、対象文字列:セルA3の値を13文字以内の適当な文字に書きかえて、Pythonプログラムを実行して、
ある文字列が左端から右端まで順に1文字ずつ分解できることを確かめてみてください。